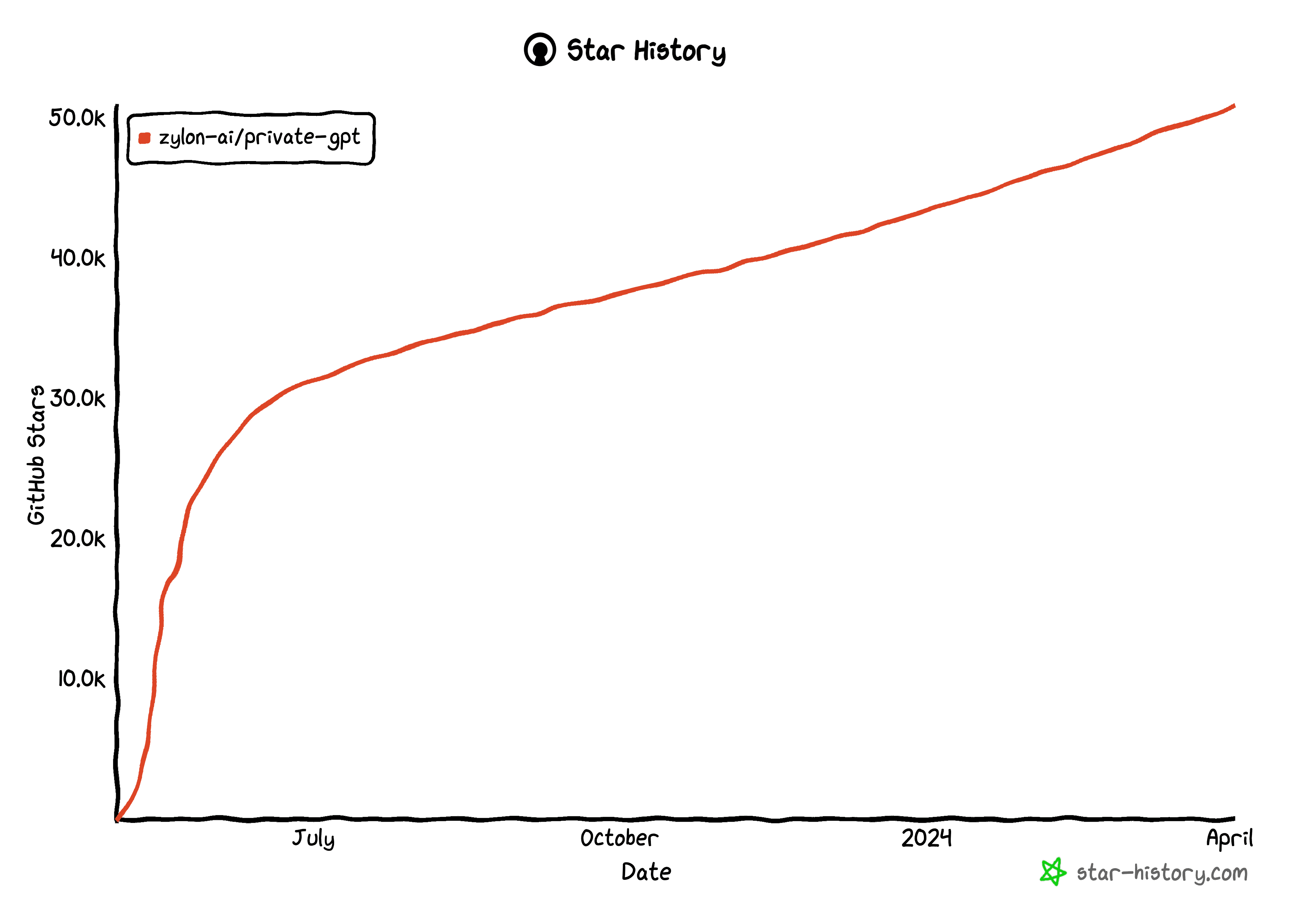
PrivateGPT v0.5.0 at 50K GitHub stars
Apr 18, 2024

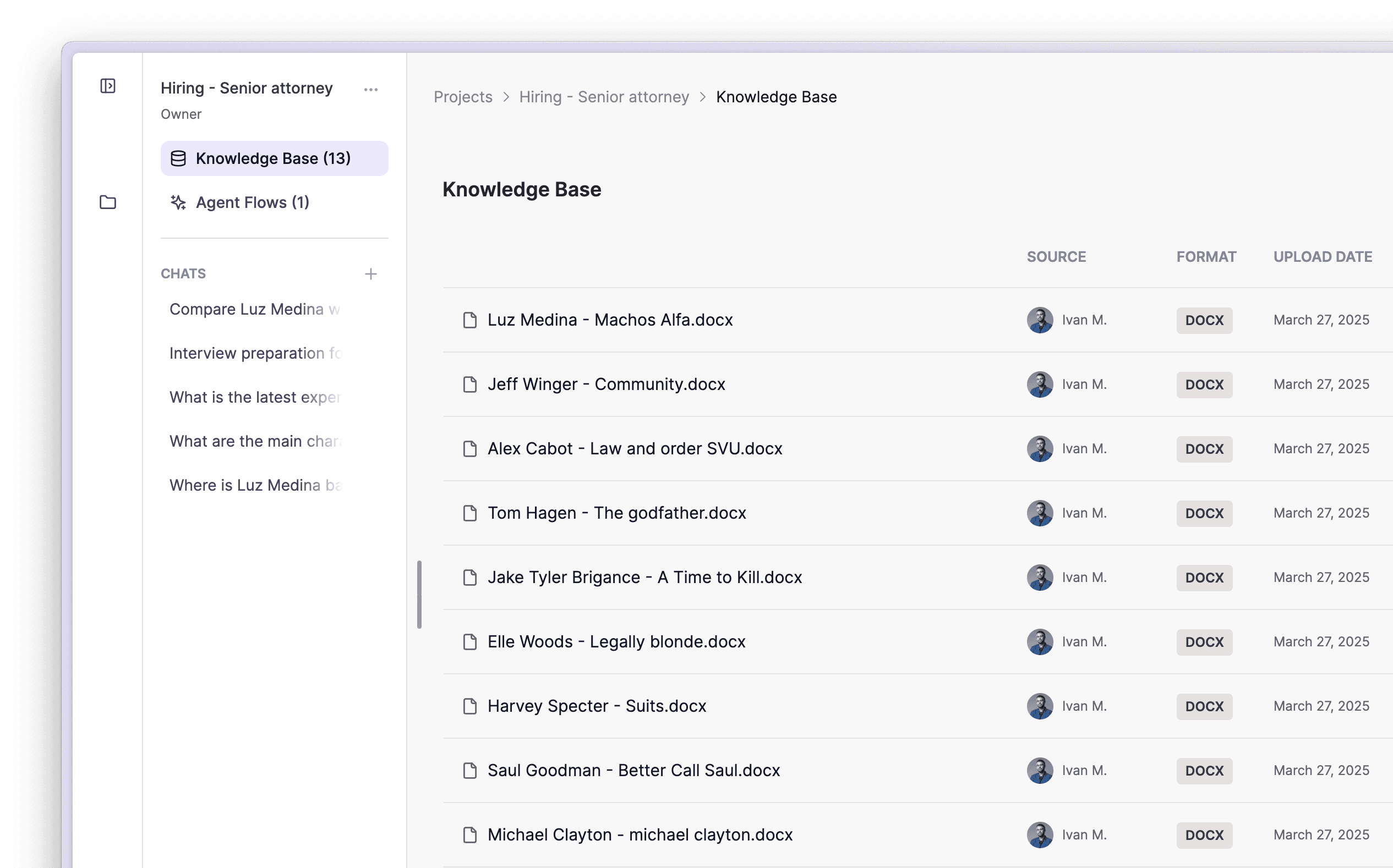
PrivateGPT reaches 50K Stars on GitHub!
PrivateGPT has recently reached an impressive milestone of 50,000 stars on GitHub. This achievement reflects the growing interest and trust in the project's potential to provide a private and secure framework to build production-ready GenAI applications.
At Zylon, we use PrivateGPT to power our easy-to-use, enterprise-ready AI-powered collaborative workspace. And just like us, dozens of teams around the world are using PrivateGPT every day as the base to create their fully private, AI-powered applications.
PrivateGPT's community is more active than ever, with more than 25 merged contributions in the last month!
Congratulations to everyone that is part of the project. We are already 4,000 people sharing GenAI ideas, experiences and best practices in Discord every day.
PrivateGPT v0.5.0
In this blog post, we'll summarize the most impactful improvements that have been integrated into PrivateGPT v0.5.0.
For a full list of features and bug fixes, visit https://github.com/zylon-ai/private-gpt/releases/tag/v0.5.0
UI Improvements
- The startup is now 10x faster. PrivateGPT heavy users with hundreds of ingested documents will really notice the difference.
- The used Model is shown in the top of the chat window.
- The score order is maintained in the returned sources.
- Duplicated sources are removed from the sources list.
LLM support Improvements
- Azure OpenAI support has been added for LLM and Embeddings.
- Model customization support for LlamaCPP and Ollama (temperature, top_k, top_p, etc.).
- Ollama LLM and Embeddings configuration have been decoupled, allowing for separate instances of Ollama being used. Longer keep-alive settings have been introduced for Ollama.
- A timeout setting for Ollama has been implemented, to allow for more time-consuming inferences.
- Tiktoken cache is now within the repo for full offline use.
RAG Improvements
- similarity_top_k and similarity_score have been exposed to settings, allowing for a more configurable retrieval of context.
- The SentenceTransformer Reranker has been introduced as an optional way to improve the context being passed to the LLM.
Ingest Improvements
- A faster ingestion mode called pipeline has been created, achieving 2x the speed of our previously fastest ingestion mode (paralell), and more than 3x the speed of the basic simple ingestion approach.
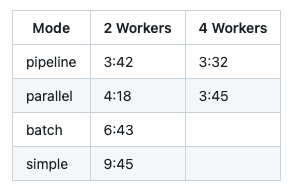
Ingesting 434 documents (144Mb) into Postgres using Ollama with nomic-embed-text for embeddings
Database Improvements
- Postgres can now be used as the single database, containing both vector storage and node storage. This is a great option for setups requiring a single database.
- Wipe utils per storage type (simple, qdrant, chroma and postgres) has been implemented to ease up resetting the database contents.
- A stats script has been added to have a better understanding of the database usage:

python scripts/utils.py stats
Docs Improvements
- A guide for Linux AMD GPU support has been added.
Contributors
v0.5.0 top contributors:
We would like to express our deepest gratitude to the entire PrivateGPT community for their continuous support, contributions, and dedication to making this project a success. Your feedback and suggestions have been invaluable in shaping the future of PrivateGPT. Stay tuned for more exciting updates and improvements!