
Veröffentlicht am
·
8 Minuten
Wir präsentieren PrivateGPT 1.0: Das Open-Source-Anwendungs-Backend für private KI

Ivan Martinez

Kurze Zusammenfassung
Im Jahr 2023 wurde PrivateGPT zur ersten jemals entwickelten Offline-RAG-Implementierung und zum meistgelesenen Repo auf GitHub. Dann wurde es ruhig um uns, wir haben unser eigenes Projekt geforkt und zwei Jahre lang daran gearbeitet, wie man private KI in großem Maßstab umsetzt. Heute führen wir alles wieder zusammen. Das Ergebnis ist PrivateGPT 1.0: eine vollständige Anwendungs-API-Schicht für lokale KI, die über jedem Inferenzserver platziert werden kann. Sie bietet Entwicklern dieselben Bausteine wie Cloud-KI-APIs, läuft jedoch vollständig auf ihrer eigenen Infrastruktur.
Einige Open-Source-Projekte sind interessante Experimente.
Andere werden zum Beweis dafür, dass ein Problem real ist.
Als wir das ursprüngliche PrivateGPT im Jahr 2023 veröffentlichten, erreichte es fast sofort den ersten Platz in den GitHub-Trends. Es war die erste Implementierung, mit der man eine vollständige RAG-Pipeline offline ausführen konnte, ohne Cloud-Abhängigkeit und ohne dass Daten den eigenen Rechner verließen. Damals hatte selbst der CEO von Langchain öffentlich erklärt, dass das Ausführen lokaler Open-Source-Modelle für reale Anwendungen noch nicht wirklich machbar sei. PrivateGPT bewies das Gegenteil, und die Community reagierte.
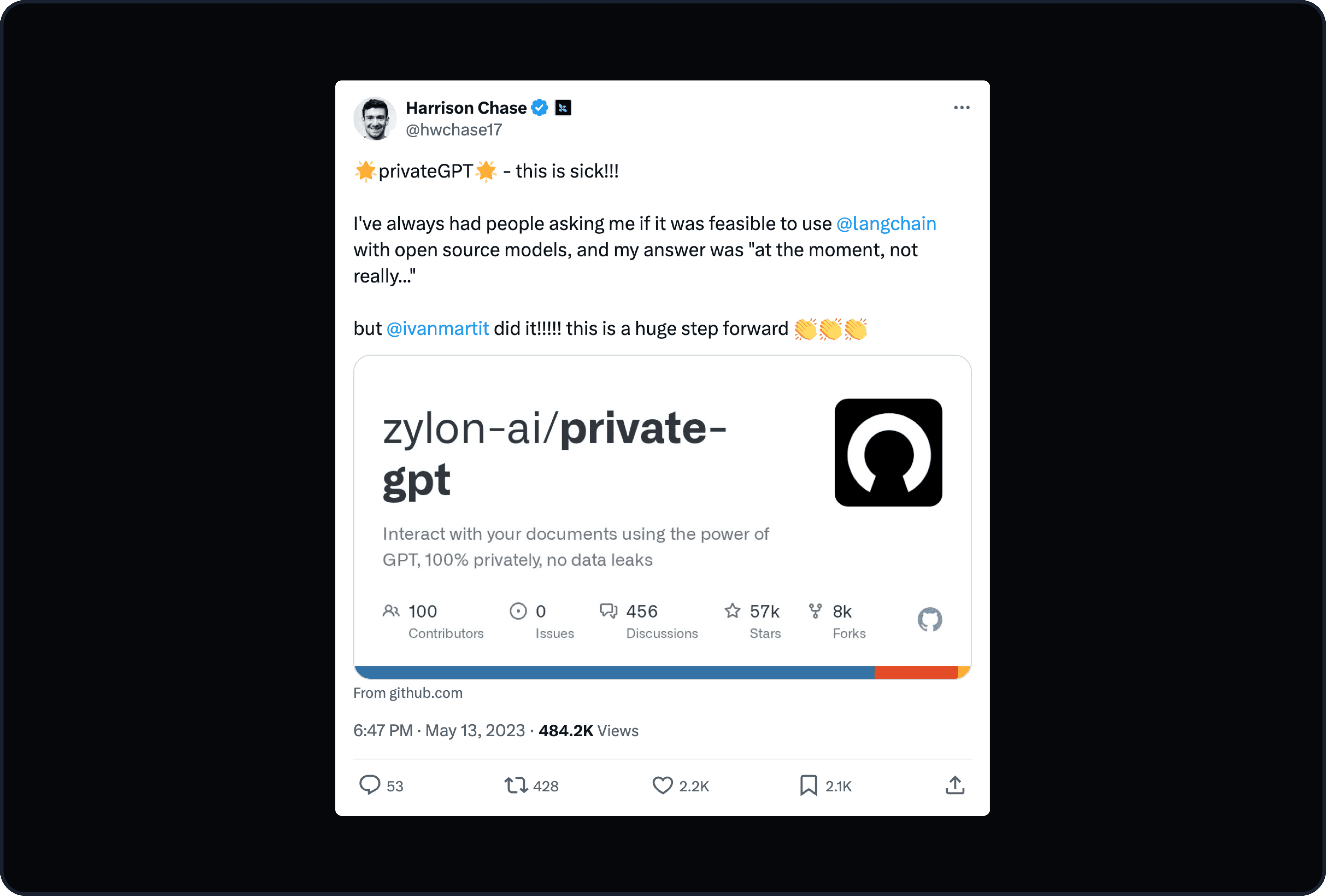
Dieser Moment bestätigte etwas Wichtiges: Die Nachfrage nach privater, lokaler KI war keine Nischenpräferenz. Es war ein fundamentales Bedürfnis, das der Markt noch nicht angemessen adressiert hatte.
Also beschlossen wir, noch viel weiter zu gehen.
Die zwei Jahre stiller Arbeit
Nach dieser ersten Explosion des Interesses trafen wir eine bewusste Entscheidung. Anstatt ein beliebtes, aber begrenztes Projekt öffentlich weiterzuentwickeln, forkten wir unser eigenes Repo und begannen, im Geheimen zu bauen.
Der ehrliche Grund war, dass es zu viele Unbekannte gab, um verantwortungsvoll im Offenen zu iterieren. Welche Modellarchitektur würde sich mit der Zeit behaupten? Was war der richtige Tech-Stack? Welcher Indexierungsansatz funktionierte im großen Maßstab? Agenten oder Workflows? Wie verwaltet man langen Kontext, ohne die Kohärenz zu verlieren? Tool-Aufrufe waren kaum standardisiert, MCP existierte noch nicht, und Harnesses als Konzept kamen gerade erst auf.
Wir mussten ausprobieren, scheitern und wiederholen, und das in einem Tempo, das eine aktive Open-Source-Community gestört hätte. Deshalb haben wir die beiden Pfade bewusst getrennt.
Zwei Jahre lang haben wir unter der Marke Zylon hunderte von Iterationen auf dem privaten KI-Stack durchgeführt. Wir haben PrivateGPT nicht nur überarbeitet. Wir haben die vollständige Infrastrukturebene aufgebaut und validiert, die für Unternehmen in den Bereichen Finanzdienstleistungen, Verteidigung, Gesundheitswesen und Behörden erforderlich ist, um Private KI tatsächlich in der Produktion einzusetzen. Echte Implementierungen, echte Compliance-Anforderungen, echte Air-Gap-Einschränkungen, echte Enterprise-Workloads.
Diese Arbeit hat uns Dinge gelehrt, die man auf andere Weise nur sehr schwer lernen kann.
Warum jetzt
Der Zeitpunkt dieser Veröffentlichung ist nicht willkürlich.
Das KI-Ökosystem ist so weit ausgereift und konvergiert, dass mehrere Dinge nun gleichzeitig zutreffen. Die Modellqualität auf lokaler Ebene hat sich drastisch verbessert. Standards wie OpenAI-kompatible APIs sind fest etabliert. Die Tools rund um strukturierten Output, Function Calling und Orchestrierung haben sich stabilisiert.
Auch auf der Nachfrageseite hat sich etwas verschoben. Datenschutz und Souveränität haben sich von einem bloßen Compliance-Häkchen zu einem strategischen Anliegen entwickelt. Enterprise-KI-Projekte geraten nicht ins Stocken, weil die Modelle zu schwach sind, sondern weil Rechts-, Sicherheits- und Infrastrukturteams die Freigabe für das Senden sensibler Daten an externe APIs nicht erteilen können. Das ist kein theoretisches Risiko mehr. Es ist ein wiederkehrendes Hindernis bei der Einführung von KI in Unternehmen, über alle Branchen und Regionen hinweg.
Gleichzeitig sind tokenbasierte Cloud-Kosten im großen Maßstab genuinely schwer zu rechtfertigen. Was als erschwingliches Pilotprojekt beginnt, wird bei steigender Nutzung zu einem ernsthaften Budgetposten, und Organisationen haben nur sehr begrenzte Kontrolle darüber, wie sich diese Preisgestaltung entwickelt.
Private KI adressiert beide Probleme direkt. Und PrivateGPT 1.0 ist die vollständigste Open-Source-Implementierung dieser Vision, die wir je veröffentlicht haben.
Was PrivateGPT 1.0 eigentlich ist
Ein Modell lokal auszuführen ist ein erster Schritt. Es reicht nicht aus.
Um nützliche KI-Anwendungen zu erstellen, benötigt man eine Reihe von Funktionen auf höherer Ebene. Eine Standard-Messages-API. Datei- und Dokumenten-Ingestion. Retrieval mit Quellenangaben. Tool-Nutzung und benutzerdefinierte Tool-Definitionen. MCP-Konnektoren. Strukturierter Zugriff auf Datenbanken und CSV-Dateien. Websuche und -extraktion. Code-Ausführung. Token-Zählung, Embeddings und asynchrone Workflows.
Bislang mussten Entwickler, die mit lokaler Inferenz arbeiteten, diese Ebene selbst erstellen oder eine Cloud-KI-API nutzen und den Kompromiss bei der Datensouveränität akzeptieren. PrivateGPT 1.0 beseitigt diese Wahl.
Das Ziel des Projekts ist es, eine Claude-äquivalente Anwendungs-API auf Ihre eigene Infrastruktur zu bringen, damit Sie private KI-Produkte ohne Abhängigkeit von Cloud-Anbietern entwickeln können.
PrivateGPT 1.0 führt Modelle nicht selbst aus. Es sitzt über jedem OpenAI-kompatiblen Inferenz-Server wie Ollama, vLLM, llama.cpp oder LM Studio und stellt darauf eine vollständige Anwendungs-API bereit. Die Architektur ist bewusst einfach gehalten:
Ihre App / Agent / Workflow / UI | PrivateGPT 1.0 API | Selbstgehosteter LLM-Server (Ollama, vLLM, etc.)
Sie wählen das Inferenz-Backend. PrivateGPT kümmert sich um alles darüber.
Wo sich PrivateGPT im Stack einordnet
Es gibt bereits hervorragende Projekte, die angrenzende Probleme lösen, und es lohnt sich, genau darzustellen, wo PrivateGPT im Vergleich zu ihnen steht.
Ollama, vLLM, llama.cpp, LM Studio übernehmen die Inferenz. Sie beantworten die Frage: Wie führe ich ein Modell aus? PrivateGPT ersetzt sie nicht. Es baut auf ihnen auf. Nutzen Sie beides zusammen: Lassen Sie Ihren bevorzugten Inferenz-Server darunter laufen und nutzen Sie PrivateGPT als Anwendungs-Backend darüber.
Onyx und Open WebUI sind Workspace-Anwendungen. Es sind App-First-Erfahrungen, die sich auf Chat und Enterprise-Suche konzentrieren. Sie sind wirklich nützliche Produkte. Aber PrivateGPT agiert auf einer anderen Ebene. Es versucht nicht, die endgültige Benutzeroberfläche zu sein. Es ist die API-Ebene unter diesen Arten von Produkten: das standardisierte lokale Backend, das Nachrichten, Dateien, Retrieval, Tool-Nutzung, Datenanalyse und Orchestrierung verwaltet. PrivateGPT wird mit einer leichtgewichtigen Benutzeroberfläche zu Testzwecken ausgeliefert, aber die API ist das eigentliche Produkt.
Am einfachsten ausgedrückt: Inferenz unten, Apps oben, PrivateGPT in der Mitte.
Volle Kompatibilität mit den Tools, die Sie bereits nutzen
Da PrivateGPT die vollständige Claude-API-Spezifikation implementiert, funktioniert es nativ mit jedem Client oder Tool, das mit Claude integriert ist, einschließlich Anthropics eigenen First-Party-Apps. Das bedeutet, dass Claude Code, Cowork und die MS-Office-Add-Ins für Word, Excel und PowerPoint alle mit einer PrivateGPT-Instanz ausgeführt werden können, wobei alle Berechnungen und Daten in Ihrer eigenen Infrastruktur verbleiben.
Standardmäßige lokale Inferenz-Server können diese Tools heute nicht unterstützen, da ihnen wichtige API-Funktionen wie strukturierter Output, Tool-Nutzung und Tokenizer-Endpunkte fehlen. PrivateGPT deckt all das ab.
Über Claude-kompatible Tools hinaus ist PrivateGPT natürlich auch mit dem breiteren Ökosystem von Tools kompatibel, die um lokale Inferenz-Anbieter herum aufgebaut sind: n8n, OpenCode, OpenClaw, Hermes, VSCode, Cline und andere.
Was dies für Zylon bedeutet
Es gibt noch eine weitere Änderung, die für uns genauso wichtig ist wie die technische Veröffentlichung.
Unser kommerzielles Produkt, Zylon.ai, wird nun unter der Haube auf Open-Source-PrivateGPT laufen. Wir haben unseren privaten Fork geschlossen. Von nun an werden wir PrivateGPT in der Öffentlichkeit iterieren, und die Arbeit, die wir auf der kommerziellen Seite leisten, wird wieder in das Open-Source-Projekt zurückfließen.
Das ist keine Marketing-Aussage. Es ist eine strukturelle Verpflichtung. Die Community kann genau sehen, was wir bauen, dazu beitragen und uns dafür in die Pflicht nehmen. Der kommerzielle Erfolg von Zylon ist nun direkt mit der Gesundheit des Open-Source-Projekts verknüpft. Diese Ausrichtung ist uns wichtig.
Für die Entwickler und Organisationen, die PrivateGPT seit den Anfangstagen verfolgen, schließt sich hier der Kreis: Zwei Jahre hart erarbeitete Erkenntnisse aus echten Unternehmenseinsätzen fließen zurück in die Community, die das überhaupt erst möglich gemacht hat.
Was als Nächstes kommt
PrivateGPT 1.0 ist das Fundament. Die Roadmap von hier aus umfasst tiefere agentische Fähigkeiten, breitere Anbieterunterstützung, mehr integrierte Tools und eine engere Integration mit den Bereitstellungsmustern, die wir in regulierten Branchen durch Zylon validiert haben.
Wenn Sie ein Entwickler sind, der KI-Anwendungen auf lokaler Infrastruktur erstellt, bietet Ihnen PrivateGPT 1.0 das Backend, das Ihnen gefehlt hat.
Wenn Sie eine Organisation sind, die private KI der Enterprise-Klasse mit Produktions-Support, Compliance-Dokumentation und dem vollständig verwalteten Stack benötigt, ist Zylon genau dafür gebaut.
Das Open-Source-Projekt und das kommerzielle Produkt teilen sich nun denselben Kerncode, der gemeinsam im Offenen entwickelt wird.
Wir freuen uns, wieder da zu sein.
Veröffentlicht am
Geschrieben von
Ivan Martinez


