
Veröffentlicht am
·
7 Minuten
Token-Effizienz wird in KI-Entwickler-Workflows zu einem echten Vorteil

Francisco García Sierra
Kurze Zusammenfassung
Die Einführung von KI-Coding geht nicht mehr nur darum, bessere Modelle zu verwenden. Es geht zunehmend darum, bessere Pipelines darum herum aufzubauen. In diesem Beitrag vergleichen wir einen grundlegenden Repository-Workflow mit einem Setup, das durch Distill, graphbasierte Repository-Navigation und präzisere Agentenanweisungen verbessert wurde. Das Ergebnis ist nicht nur ein geringerer Tokenverbrauch, sondern auch weniger Rauschen, schnellere Iterationen und ein besseres Signal bei den Teilen der Aufgabe, die wirklich zählen.
Die KI-Coding-Diskussion wird immer noch von der Modellqualität dominiert.
Das ergibt Sinn. Frontier-Modelle sind inzwischen wirklich gut. GPT-5.4, Claude Opus 4.6 und die neuesten High-End-Coding-Modelle können in realen Engineering-Workflows bereits spürbare Ergebnisse freischalten.
Aber es gibt eine weitere Variable, die genauso wichtig zu werden beginnt: wie viel es kostet, wie lange es dauert und wie sauber das Signal ist, wenn man zu einem brauchbaren Ergebnis kommt.
Kosten sind wichtig, egal ob du ein kleines Team, ein mittelständisches Unternehmen oder eine große Organisation bist, die ihr Budget einfach nicht verschwenden will. Geschwindigkeit ist wichtig, weil niemand warten will, während ein Agent Lärm noch einmal liest. Und Qualität ist wichtig, weil du beim Reduzieren nutzloser Token-Nutzung normalerweise auch Rauschen reduzierst, die Granularität der Themen verbesserst, die wirklich zählen, und die finale Antwort leichter vertrauenswürdig machst.
Das zeigt sich meistens als:
vollständige Testlogs, die zurück in die Schleife fließen
ausführliche Tool-Ausgaben für kleine Entscheidungen zum nächsten Schritt
wiederholte Repo-Erkundung nach Kontextkomprimierung
Agenten, die dieselben Routen, Services und DTOs immer und immer wieder neu entdecken
große Codebasen, die erneut gelesen werden, obwohl die Aufgabe nur eine schmale Antwort braucht
Für eine Weile konnten viele Teams diese Steuer ignorieren. Credits waren großzügig. Pricing wirkte nachsichtig. KI-Nutzung war noch experimentell.
Das ändert sich bereits.
OpenAI führte den Codex-App mit einer befristeten Phase höherer Codex-Rate-Limits ein, dann verschob ChatGPT Business in Richtung token-angepasster Codex-Preisgestaltung und flexibler Codex-only-Seats. Das ist ein gutes Beispiel für die Richtung, in die sich der Markt bewegt: weniger schwammige gebündelte Magie, mehr Transparenz über die tatsächliche Nutzung und die tatsächlichen Ausgaben.
Anthropic ist auch ziemlich klar, dass Claude-Code-Kosten etwas sind, das Teams verfolgen und managen sollten, und dass der Teamzugang an bestimmte Seat-Typen und Abrechnungsentscheidungen gebunden ist.
Und auch dort verändert sich die Verpackungsgeschichte. Am 4. April 2026 sagte Boris Cherny, Leiter von Claude Code, auf X, dass Claude-Abonnements die Nutzung von Tools wie OpenClaw nicht mehr abdecken würden, wobei diese Nutzung in zusätzliche Bundles oder API-Abrechnung übergeht. Ob du dieser Änderung zustimmst oder nicht, sie unterstreicht denselben Punkt: Governance über deine Pipeline, deine Integrationen und deine Token-Nutzung wird Teil der Arbeit. Er präzisierte denselben Punkt in einem Folgebeitrag.
Dieses Fenster schließt sich.
Sobald KI Teil der täglichen Entwicklung innerhalb eines Unternehmens wird, hört die Token-Nutzung auf, nur eine Nebenmetrik zu sein, und wird Teil von Betriebskosten, Latenz und Durchsatz. Die Unternehmen, die ihre Pipelines frühzeitig in Ordnung bringen, holen mehr Wert aus denselben Modellen, denselben Budgets und denselben Entwicklerstunden heraus.
Das war die Motivation hinter einem kleinen Benchmark, den wir in einem unserer täglichen Backend-Workflows durchgeführt haben.
Das Ziel war nicht, das Modell "klüger" zu machen. Es war, die Pipeline weniger laut zu machen.
Wir haben uns auf drei Hebel konzentriert:
Distillation Skill, eine Fähigkeit, die wir auf Basis des Distill-Projekts gebaut haben, um lange Ausgaben, CLI-Lärm und wiederholtes MCP-Geplapper auf das Minimum zu reduzieren, das ein Agent für den nächsten Schritt wirklich brauchtGraph Skill, das Graphify verwendet, um einen Wissensgraphen des Repos zu erzeugen und Dateien samt ihrer Beziehungen als Knoten zu indexieren, sodass der Agent eine Domäne abbilden kann, ohne alles von Grund auf neu zu erkundeneine straffere
AGENTS.md, um den Agenten zu schmaleren, wertvolleren Erkundungsmustern zu lenken
Der umfassendere Task-Benchmark
Wir haben denselben Prompt dreimal über drei Setups hinweg ausgeführt und die Ergebnisse gemittelt.
Zur besseren Lesbarkeit verwende ich diese öffentlich sichtbaren Namen:
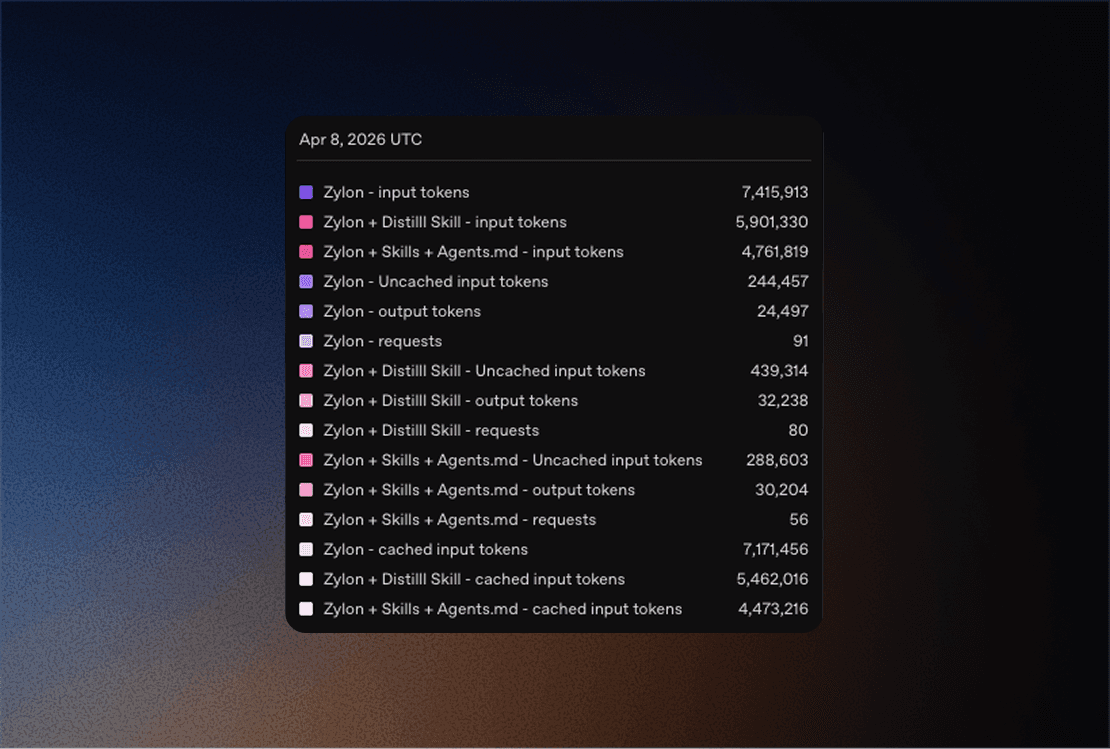
Setup | Durchschnittliche Laufzeit | Eingabe-Tokens | Ausgabe-Tokens | Anfragen |
|---|---|---|---|---|
Basislinie | 12m 30s | 7,415,913 | 24,497 | 91 |
Basislinie + Destillation | 11m 19s | 5,901,330 | 32,238 | 80 |
Basislinie + Destillation + Graph | 9m 10s | 4,761,819 | 30,204 | 56 |
Im Vergleich zur Basislinie:
Baseline + Distillationverwendete20.42%weniger Eingabe-Tokens, machte12.09%weniger Anfragen und war9.47%schneller fertigBaseline + Distillation + Graph Skillverwendete35.79%weniger Eingabe-Tokens, machte38.46%weniger Anfragen und war26.67%schneller fertig
Das ist die Schlagzeile.
Aber Durchschnittswerte über eine ganze Aufgabe hinweg können verbergen, wo die größten Gewinne tatsächlich herkommen.
Der interessante Teil zeigt sich, wenn man die lautesten Teil-Workflows isoliert.
Mikro-Benchmarks: Wo die größten Einsparungen sichtbar werden
1. Einen lauten Testlauf destillieren
Für den ersten Mikro-Benchmark haben wir ein absichtlich lautes Ziel verwendet:
./gradlew :server:Test --tests backend.server.app.project.ProjectTest
Um den Vergleich fair zu halten, haben wir die Suite nicht einmal roh und einmal destilliert erneut ausgeführt. Das hätte eine Warm-Cache-Verzerrung eingeführt.
Stattdessen haben wir:
die Test-Suite einmal ausgeführt
die rohe Ausgabe gespeichert
genau dieses gespeicherte Log destilliert
Damit wird der Effekt der Kontextkomprimierung von der Gradle-Ausführungsvarianz getrennt.
Wir haben das Token-Volumen mit einer einfachen characters / 4-Heuristik geschätzt.
Ansicht | Laufzeit | Zeilen | Zeichen | Geschätzte Tokens |
|---|---|---|---|---|
Rohes | 24.02s | 1,074 | 358,678 | 89,669.50 |
Destillierte Zusammenfassung desselben Logs | 15.01s | 4 | 240 | 60.00 |
Das heißt:
99.93%weniger Zeichen, die dem Agenten präsentiert wurdenein
1,494.49x-Kompressionsfaktor
Im erfassten Lauf war der fehlschlagende Test projects can be order by name(), und die destillierte Zusammenfassung stimmte mit dem XML-Ergebnis überein, das wir zur Validierung verwendet haben.
Das ist die Art von Verbesserung, die in breiteren Durchschnittswerten untergeht. Wenn die Aufgabe lautet "führe eine Suite aus und entscheide, was wichtig ist", sind rohe Logs normalerweise einer der schlechtesten Orte, um Premium-Reasoning-Tokens auszugeben.
Hier ist eine kompakte Vorher/Nachher-Ansicht desselben Laufs.
Ohne Distill sieht der Agent einen langen Strom und muss den nützlichen Teil selbst herausfiltern:
Wenn die Suite erfolgreich ist, bekommst du trotzdem denselben Stil von langem Anwendungs- und Test-Output. Wenn sie fehlschlägt, bekommst du das plus den Stacktrace, aber immer noch keine kompakte Antwort darauf, was als Nächstes wirklich wichtig ist.
Mit Distill wird derselbe Lauf entscheidungsbereit:
Und wenn der Lauf sauber ist, kann die Form genauso klein bleiben:
2. Einen Projektbereich mit Shell-Befehlen vs. Graphify erkunden
Der zweite Mikro-Benchmark konzentrierte sich auf Repo-Erkundung.
Frage:
Wie sind Standard-Projektrollen und die Übertragung des Besitzes im Projektbereich implementiert?
Für die Shell-basierte Version haben wir den Workflow realistisch und diszipliniert gehalten:
ein gezieltes
rggezielte Ausschnitte aus
ProjectRoutes.ktgezielte Ausschnitte aus
ProjectService.ktgezielte Ausschnitte aus
ProjectRepository.ktdas
ProjectMemberRole.kt-Enum
Für die graphbasierte Version haben wir den server-app-project-Scope neu aufgebaut und eine Graphify-Abfrage zur selben Frage ausgeführt.
Auch hier haben wir das Token-Volumen mit characters / 4 geschätzt.
Ansicht | Zeilen | Zeichen | Geschätzte Tokens |
|---|---|---|---|
Realistisches Shell-Erkundungspaket | 352 | 17,252 | 4,313.00 |
Graphify-Abfrageausgabe | 25 | 4,239 | 1,059.75 |
Das heißt:
75.43%weniger Zeichen für die graphbasierte Erkundungsansichteine
4.07x-Reduktion in diesem realistischen Erkundungslauf
Und das ist der praktische Unterschied.
Ohne Graph bedeutet selbst ein disziplinierter Erkundungsfluss immer noch, mehrere Suchen und Dateilesevorgänge zu verketten:
Das sind 6 separate Lese-/Abfragevorgänge, nur um ein erstes brauchbares Bild der Domäne zu bekommen.
Mit dem bereits aufgebauten Graphen wird der Startpunkt viel kleiner:
Und die zurückgegebenen Knoten sind bereits um die interessanten Konzepte herum geclustert:
Das ersetzt keine Quellcode-Inspektion. Es gibt dir nur eine deutlich bessere erste Einschätzung, worauf du deine Aufmerksamkeit richten solltest.
Der Graph ist leichter zu verstehen, wenn du ihn als kleine Karte und nicht als rohes JSON betrachtest.
In diesem Fall sieht ein nützlicher Cluster ungefähr so aus:
Und die Relationsebene ist das, was ihn nützlich macht:
Das bedeutet, der Graph sagt uns nicht nur "hier sind einige Dateien". Er sagt uns auch, welche Dateien zentral sind, welche Konzepte darin leben und welche Cluster zum selben Thema gehören.
Genau deshalb funktioniert graphbasierte Erkundung hier so gut: Sie gibt dem Agenten eine Karte dessen, was existiert und wie die Teile zusammenhängen, bevor er Datei für Datei öffnet.
Das ist die ehrlichere "Engineer-Workflow"-Geschichte.
Wir haben außerdem Graphifys eingebauten Benchmark auf demselben Umfang als separate unterstützende Datengrundlage laufen lassen. Dieses Tool schätzte:
einen naiven Korpusdurchlauf auf
~39,533Tokenseine durchschnittliche Graphify-Abfragekosten von
~1,256Tokenseine
31.5x-Reduktion pro Abfrage
Diese Zahl ist nützlich, aber sie ist nicht dasselbe wie der realistische Shell-Vergleich oben, deshalb trennen wir sie absichtlich.
Warum das heute wichtiger ist als früher
Ein großer Teil der KI-Kosten wird heute noch durch Produktverpackung verborgen.
Wenn die Stückkosten durch Credits, gebündelte Preise oder experimentelle Budgets aufgeweicht werden, fühlt sich Verschwendung nicht dringend an. Teams konzentrieren sich darauf, ob der Workflow überhaupt funktioniert, nicht darauf, ob er sauber skaliert.
Aber sobald KI im Engineering-Org normal wird, akkumuliert sich die Verschwendung:
jeder Testlauf
jeder Repo-Erkundungslauf
jeder Tool-Call eines Agenten
jeder Retry, der durch überladenen Kontext verursacht wird
jeder Entwickler, der das System jeden Tag nutzt
An diesem Punkt hört Token-Effizienz auf, eine nette Optimierung zu sein, und wird zu operativer Hygiene.
Das gilt genauso für private und lokale Deployments. Selbst wenn das Modell intern läuft, frisst Pipeline-Verschwendung trotzdem Durchsatz, erhöht die Latenz und senkt die Anzahl der nützlichen Aufgaben, die du gleichzeitig ausführen kannst.
Was hier tatsächlich die Verschwendung reduziert hat
Dieser Benchmark beruhte nicht auf einem magischen Prompt.
Er entstand durch das Straffen von drei Ebenen des Workflows:
Destillation
Destillation ist nützlich, wenn die Ausgabe groß ist, aber die nächste Entscheidung klein.
Typische Beispiele:
Testläufe
Stacktraces
ausführliche Build-Ausgaben
lange Diffs
Logs
Das Modell sollte Denkleistung auf die Entscheidung verwenden, nicht auf Tausende von Zeilen Boilerplate.
Graphbasierte Erkundung
Graphify ist kein Ersatz für direkte Quellcode-Inspektion.
Es ist nützlich, wenn die Frage strukturell ist:
Wo soll ich anfangen?
Was verbindet X mit Y?
Welche Dateien sind hier zentral?
Wie engere ich diese Domäne ein, bevor ich Dateien öffne?
Das ist in großen Repos wichtig, in denen die eigentliche Steuer nicht das Bearbeiten, sondern die Navigation ist.
AGENTS.md / CLAUDE.md
Ein gutes AGENTS.md/CLAUDE.md verändert das Verhalten des Agenten, bevor der erste teure Fehler passiert.
Es sagt dem Agenten:
wo er für eine bestimmte Aufgabe anfangen soll
wann breite Repo-Scans vermieden werden sollten
wann eng validiert werden sollte
wann
rgstatt Mapping-Tools verwendet werden sollwas "kleinstmöglicher sinnvoller Umfang" in dieser Codebasis bedeutet
Das klingt einfach, wirkt sich aber direkt auf Token-Nutzung, Latenz und Wiederholbarkeit aus.
Eine einfachere Regel für Denkaufwand
Nicht jede Aufgabe verdient maximales Nachdenken.
Hier ist die praktische Version:
Aufgabentyp | Beste Standardeinstellung |
|---|---|
Kleine bekannte Fehlerbehebung | Den Thread kurz und das Reasoning leicht halten |
Fehler mit unklarer Ursache | Vor dem Bearbeiten mehr in die Diagnose investieren |
Refactoring mit mehreren beweglichen Teilen | Erst höher aufwandige Planung verwenden, dann wenn möglich günstigere Ausführung |
Große Repo-Erkundung | Zuerst Karten und Zusammenfassungen verwenden, nicht rohe Code-Dumps plus maximales Reasoning |
Das richtige Ziel ist nicht "überall härter denken".
Es ist "tiefes Reasoning dort ausgeben, wo es Fehler-Schleifen verhindert, und überall sonst Verschwendung reduzieren".
Denn hoher Denkaufwand bei jeder Aufgabe hat auch Nebenwirkungen:
er kostet mehr
er antwortet meist langsamer
er kann einfache Aufgaben überanalysieren, die direkt hätten gelöst werden sollen
er kann in breitere Pläne abdriften, wenn die Aufgabe nur eine kleine Änderung brauchte
er kann das eigentliche Problem unter viel zusätzlichem Text verstecken
Mehr ist nicht immer besser. Viele Leute gehen standardmäßig auf maximalen Aufwand, weil es sich sicherer anfühlt, aber in der Praxis kann das den Workflow langsamer, lauter und weniger fokussiert machen.
Der kumulative Effekt
Der breitere Benchmark zeigte bereits, was eine sauberere Pipeline in einer realistischen gemischten Aufgabe leisten kann: 35.79% weniger Eingabe-Tokens und 26.67% schnellere Fertigstellung im stärksten Setup.
Die Mikro-Benchmarks zeigen etwas noch Wichtigeres:
laute Testläufe können dramatisch komprimiert werden
Repo-Erkundung kann eingegrenzt werden, bevor das Modell zu viel liest
Genau so werden kleine Workflow-Verbesserungen im Laufe der Zeit zu großen operativen Einsparungen.
Eine Verbesserung pro Tag klingt gering.
Aber ein bloatiger Testlauf weniger, ein engerer Suchdurchlauf, eine bessere Repo-Anweisung, eine redundante Leseschleife weniger, wiederholt über Monate hinweg in einem Team, summiert sich viel schneller, als die meisten denken.
Die Quintessenz ist einfach:
bessere Modelle sind wichtig, aber bessere Pipelines werden gerade genauso wichtig.
Wenn dein KI-Workflow zu einer täglichen Engineering-Infrastruktur werden soll, ist jetzt der richtige Moment, das Rauschen zu reduzieren, bevor die Kostenkurve die Entscheidung für dich trifft.
Autor: Francisco Garcia Sierra, Full-Stack-Entwickler bei Zylon
Veröffentlicht: April 2026
Francisco ist ein Full-Stack-Entwickler bei Zylon, der an Produkt, Infrastruktur und KI-gestützten Entwickler-Workflows arbeitet. Er hat Enterprise-Produkte end-to-end gebaut, von Backend-Systemen und APIs bis hin zu Frontend-Erlebnissen und Produktionsintegrationen, mit starkem Fokus auf den Aufbau zuverlässiger Systeme, die in realen Umgebungen skalieren. Zu seinem Hintergrund gehören auch Blockchain und Kryptografie, was seine Herangehensweise an Sicherheit, Systemdesign und Vertrauen in Software prägt. Bei Zylon arbeitet er daran, fortgeschrittene KI-Fähigkeiten in praktische Werkzeuge zu verwandeln, die die Developer Experience verbessern, operative Reibung reduzieren und Teams helfen, schneller und mit mehr Kontrolle auszuliefern.
Veröffentlicht am
Geschrieben von
Francisco García Sierra


